Optional이란? Optional은 Java 8부터 추가된 클래스로, ‘값이 있을 수도 있고 없을 수도 있다’는 개념을 명시적으로 표현하기 위해 사용됩니다. 전통적으로 Java에서 메서드가 ‘값이 없을’ 경우에는 null을 반환하거나 예외를 던져 왔습니다. 그러나 이러한 방식은 NullPointerException(NPE)의 위험이나 ‘이 메서드가 null을 반환할 수 있다’는 사실을 코드만으로는 명확히 알기 어렵다는 문제가 있었습니다.
Optional을 사용하면 다음과 같은 이점이 있습니다.
명시적 표현
‘값이 없을 수도 있음’을 Optional이란 반환 타입만으로도 알 수 있어 코드 가독성과 안정성이 향상됩니다.
메서드 반환 타입이 Optional<T>라면, 그 메서드 호출 결과가 null이 될 수도 있음을 암묵적으로 알 수 있게 됩니다.
null 처리 로직 간소화
null 체크를 직접 하기보다는 ifPresent, orElse, orElseThrow 등의 메서드를 사용하여 간결하게 처리할 수 있습니다.
이를 통해 NullPointerException 발생 가능성을 줄이고, 코드가 보다 함수형 스타일을 따르게 됩니다.
함수형 스타일 메서드 체이닝
map, flatMap, filter 같은 고차 함수들을 사용할 수 있어, 값의 존재 여부를 확인하는 반복적인 if (x != null) 구문을 대체할 수 있습니다.
언제 Optional을 사용해야 할까?
‘반환할 값이 있을 수도 없을 수도 있음’을 명확히 표현해야 하는 경우
예) findById 메서드처럼 DB나 컬렉션에서 어떤 값을 찾는데, 그 값이 존재하지 않을 수도 있는 상황에서 결과를 담는 경우.
API 설계 단계에서 메서드가 null이 될 가능성을 명시하고자 할 때
메서드에서 null을 반환할 수 있다는 사실을 주석이 아닌 타입 자체로 전달해, 오용 가능성을 줄일 수 있습니다.
값의 부재를 예외 상황으로 보고 싶지 않은 경우
예외를 던져야 할 수준은 아니지만, 그냥 null을 반환하기엔 직관적이지 않을 때 Optional을 사용합니다.
언제 사용하지 않아야 할까?
필드(멤버 변수)로 쓰지 말 것
Optional은 ‘값이 있을 수도, 없을 수도 있는 객체’를 표현하기 위한 것이지, 엔티티나 DTO의 필드를 선언할 때 쓰는 용도로 만들어진 것이 아닙니다.
필드에 Optional을 두면 직렬화/역직렬화에서 문제가 생길 수 있고, 불필요한 레퍼 객체가 중첩되어 성능이 저하될 수 있습니다.
메서드 파라미터로 사용 지양
파라미터에 Optional을 사용하기보다는 오버로딩, 기본값 설정, Builder 패턴 등을 사용하는 것이 더 권장됩니다.
컬렉션을 담는 Optional
“값이 없을 수도 있음”을 표현해야 하는 상황에서 컬렉션 자체가 이미 ‘비어 있음(empty) 또는 있음’을 표현할 수 있습니다. Optional<Collection<T>>를 사용하기보다는 빈 컬렉션을 반환하거나 null 이외의 다른 방법으로 처리하는 편이 좋습니다.
public class UserService {
private final Map<Long, User> userStore = new HashMap<>();
// Optional을 통한 반환
public Optional<User> findUserById(Long id) {
return Optional.ofNullable(userStore.get(id));
}
public void printUserName(Long id) {
Optional<User> maybeUser = findUserById(id);
// ifPresent: 값이 있으면 람다 실행
maybeUser.ifPresent(user -> System.out.println(user.getName()));
// orElse: 값이 없으면 대체값 사용
User user = maybeUser.orElse(new User("익명"));
System.out.println("유저명: " + user.getName());
// orElseThrow: 값이 없으면 예외 던지기
User userOrException = maybeUser.orElseThrow(() -> new IllegalArgumentException("유저를 찾을 수 없습니다."));
System.out.println("필수 유저명: " + userOrException.getName());
// map: 값이 있으면 변환
String userName = maybeUser.map(User::getName).orElse("No Name");
System.out.println("User Name: " + userName);
}
}
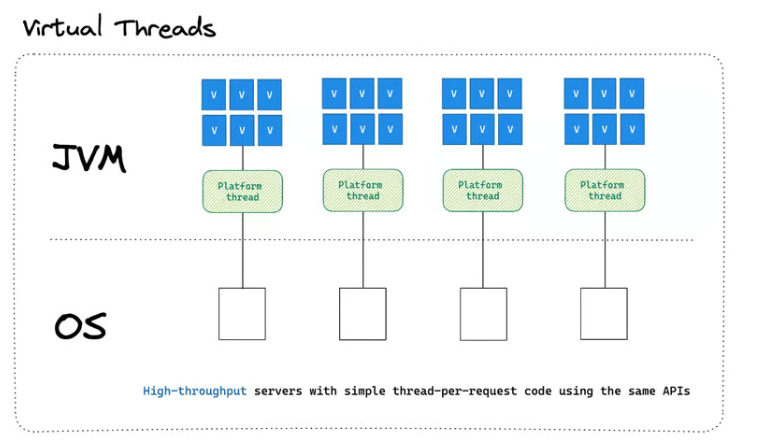
Virtual Threads는 JDK 19에서 처음 소개된 기능으로, Java의 스레드 모델을 개선하기 위한 중요한 혁신 중 하나입니다. 기존의 Java 스레드 모델은 운영 체제(OS) 레벨의 스레드를 사용하여 애플리케이션의 동시성을 처리했지만, 이 모델에는 몇 가지 한계가 있었습니다. 특히, 많은 수의 스레드를 생성할 때 메모리와 성능의 제약이 발생할 수 있었습니다. Virtual Threads는 이러한 문제를 해결하기 위해 도입되었습니다.
경량 스레드: Virtual Threads는 매우 경량화된 스레드로, 수천 또는 수만 개의 스레드를 생성하더라도 시스템 자원에 크게 부담을 주지 않습니다. 이는 기존의 OS 스레드와 비교했을 때 매우 효율적인 메모리 사용과 스케줄링을 가능하게 합니다.
비동기 코드의 동기적 표현: Virtual Threads를 사용하면, 비동기적으로 작성된 코드도 동기 코드처럼 쉽게 작성할 수 있습니다. 즉, 비동기 코드에서 흔히 사용되는 콜백(callback) 또는 복잡한 Future/CompletableFuture 체인을 사용할 필요 없이, 마치 동기 코드처럼 간단하게 비동기 작업을 처리할 수 있습니다.
운영 체제와의 분리: Virtual Threads는 Java의 사용자 레벨에서 관리되며, 운영 체제의 스레드와는 별도로 동작합니다. 이는 Java 런타임 환경에서 직접 스레드를 관리하고, OS의 스케줄러에 의존하지 않는다는 것을 의미합니다.
큰 수의 스레드 지원: Virtual Threads를 사용하면, 대규모 동시성을 필요로 하는 애플리케이션에서 수십만 개의 스레드를 효율적으로 운영할 수 있습니다. 이는 특히 서버 애플리케이션에서 많은 클라이언트 요청을 동시에 처리해야 하는 경우에 유용합니다.
간단한 사용: Virtual Threads는 기존의 Thread API와 매우 유사한 방식으로 사용할 수 있기 때문에, 개발자가 새로운 API나 개념을 학습할 필요 없이 쉽게 활용할 수 있습니다.
사용 예시
Thread.startVirtualThread(() -> {
// 여기에 작업을 수행하는 코드 작성
});
or
Thread.ofVirtual().start(() -> {
// Virtual Thread에서 실행할 코드
});
Virtual Threads의 장점
자원 효율성: 기존의 OS 스레드보다 훨씬 적은 메모리를 사용하므로, 더 많은 동시 작업을 처리할 수 있습니다.
단순성: 비동기 코드를 동기 코드처럼 작성할 수 있어 코드의 가독성과 유지보수성이 향상됩니다.
확장성: 대규모 동시성을 필요로 하는 시스템에서도 높은 성능을 유지할 수 있습니다.
Virtual Threads의 단점
스레드 수의 증가: Virtual Threads는 기존 스레드보다 훨씬 더 많은 수의 스레드를 생성할 수 있으므로, 디버깅이나 모니터링 과정에서 어떤 스레드가 어떤 작업을 수행하는지 추적하는 것이 어려울 수 있습니다. 기존의 디버깅 도구와 방법이 잘 작동하지 않을 가능성이 있습니다.
디버깅 도구의 적응 필요: 많은 디버깅 및 모니터링 도구가 전통적인 OS 스레드를 기반으로 만들어졌기 때문에, Virtual Threads에 맞춰 적응하지 못한 도구들은 효과적이지 않을 수 있습니다. 이로 인해 개발자는 새로운 도구나 방식을 배워야 할 필요가 있습니다.
블로킹 호출 문제: Virtual Threads는 기본적으로 비동기 작업을 효율적으로 처리하기 위해 설계되었습니다. 그러나 네트워크 호출이나 파일 I/O 등에서 블로킹 작업이 발생할 경우, Virtual Threads의 장점이 약화될 수 있습니다. Java 표준 라이브러리 내의 일부 API는 여전히 블로킹 방식으로 동작하기 때문에, 잘못된 사용은 성능 저하로 이어질 수 있습니다.
블로킹과 비동기 혼용의 복잡성: 기존의 코드베이스에서 블로킹 호출과 비동기 호출이 혼용되어 있을 때, 이를 Virtual Threads로 변환하는 작업은 까다로울 수 있습니다. 모든 코드가 비동기적으로 동작하도록 하려면, 코드 리팩토링이 필요할 수 있습니다.
제한된 스케줄링 제어: Virtual Threads는 Java 런타임에 의해 관리되므로, 개발자가 스레드의 우선순위나 스케줄링 정책을 세밀하게 제어하기 어렵습니다. 특정 스레드가 더 높은 우선순위를 가져야 하는 상황에서는 기존의 OS 스레드보다 제어가 어렵습니다.
컨텍스트 스위칭 오버헤드: Virtual Threads는 매우 경량화되었지만, 대규모 애플리케이션에서 여전히 컨텍스트 스위칭과 관련된 오버헤드가 발생할 수 있습니다. 이는 매우 많은 수의 Virtual Threads를 사용할 때 성능 저하로 이어질 수 있습니다.
결론
Virtual Threads는 Java 애플리케이션에서 동시성을 처리하는 방식에 큰 변화를 가져왔지만, 모든 상황에서 무조건적으로 더 나은 선택은 아닙니다. 특히, 기존 시스템과의 호환성, 디버깅 및 모니터링의 복잡성, 블로킹 작업과의 조화 문제 등을 잘 이해하고, 상황에 맞게 적절히 사용해야 합니다. 이러한 단점과 제약을 인식하고, Virtual Threads의 장점을 극대화할 수 있는 방법을 모색하는 것이 중요합니다.
hashCode() 메소드는 객체의 해시 코드를 반환합니다. 이 값은 객체를 해시 기반 컬렉션에서 사용할 때 사용됩니다. hashCode() 메소드를 오버라이드할 때는 equals() 메소드도 함께 오버라이드해야 하며, 이 둘은 다음 계약을 준수해야 합니다:
일관성: 같은 객체에 대해 여러 번 호출된 hashCode()는 항상 같은 값을 반환해야 합니다.
equals()와의 일관성: 두 객체가 equals() 메소드로 같다고 판별되면, 그들의 hashCode()는 반드시 같아야 합니다.
다름: 두 객체가 equals() 메소드로 다르다고 판별되더라도, hashCode() 값이 반드시 다를 필요는 없습니다. 그러나 다른 객체에 대해서는 가능한 한 다른 해시 코드를 반환해야 합니다.
@Override
public int hashCode() {
return Objects.hash(field1, field2);
}
예제 클래스
다음은 equals()와 hashCode() 메소드를 오버라이드한 예제 클래스입니다:
import java.util.Objects;
public class MyClass {
private int field1;
private String field2;
public MyClass(int field1, String field2) {
this.field1 = field1;
this.field2 = field2;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
MyClass myClass = (MyClass) o;
return field1 == myClass.field1 && Objects.equals(field2, myClass.field2);
}
@Override
public int hashCode() {
return Objects.hash(field1, field2);
}
}
뭐 사실 equals는 워낙 자주 사용하다보니 잘알것이다. 다만 hashcode는 한번쯤 무엇인지 확인해볼필요가 있다.
hashCode() 메소드는 주로 해시 기반 컬렉션 (예: HashMap, HashSet, Hashtable)에서 객체를 효율적으로 저장하고 검색하기 위해 사용됩니다.
일반적으로 List< HashMap> 을 자주 이용한다. 이때 hashMap의 객체의 효율적인 저장과 검색을 위해서 사용을한다.
주요 이유
빠른 데이터 검색: 해시 기반 컬렉션은 평균적으로 O(1) 시간 복잡도로 데이터를 검색할 수 있습니다. 이는 객체의 해시 코드를 사용하여 해당 객체가 위치한 버킷을 빠르게 찾을 수 있기 때문입니다.
효율적인 데이터 저장: 해시 코드를 사용하면 데이터를 저장할 때 충돌을 줄일 수 있습니다. 해시 코드가 잘 분포되면 서로 다른 객체가 동일한 버킷에 저장되는 경우가 줄어들어, 해시 테이블의 성능이 향상됩니다.
일관성: equals() 메소드와 함께 사용될 때, 해시 코드는 객체의 논리적 동등성을 일관되게 유지하는 데 도움을 줍니다. 동일한 객체는 항상 동일한 해시 코드를 가져야 하며, 그렇지 않으면 해시 기반 컬렉션의 동작이 올바르게 작동하지 않을 수 있습니다.
여기서 hashcode는 메모리 주소가 아니다. 처음에 필자는 메모리 주소 인가 했다.
hashCode()와 객체 주소의 관계
기본 구현:
Object 클래스의 기본 hashCode() 메소드 구현은 객체의 메모리 주소를 기반으로 해시 코드를 생성할 수 있습니다. 이 때문에 객체가 동일하더라도 메모리 위치가 달라지면 해시 코드가 달라질 수 있습니다. 그러나, 이 기본 구현은 대부분의 경우 재정의됩니다.
사용자 정의 구현:
대부분의 경우, 특히 해시 기반 컬렉션에서 올바르게 동작하기 위해, hashCode() 메소드는 객체의 상태(예: 필드 값)에 기반하여 해시 코드를 생성하도록 오버라이드됩니다. 이 경우, hashCode()는 객체의 메모리 주소와는 무관하게 객체의 내용을 기반으로 해시 코드를 계산합니다
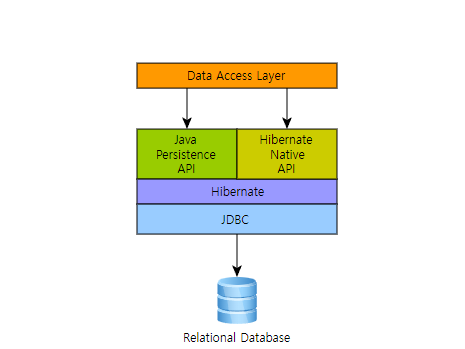
먼저 hibernate 란 뭘까? Hibernate는 자바 기반의 객체 관계 매핑(ORM) 라이브러리입니다. ORM은 객체 지향 프로그래밍 언어를 사용하여 데이터베이스와의 상호작용을 추상화하는 프로그래밍 기법 중 하나로, 개발자가 객체 지향적인 방식으로 데이터베이스를 다룰 수 있게 해줍니다. Hibernate는 이 ORM을 구현한 대표적인 프레임워크 중 하나입니다. Hibernate의 주요 목적은 Java 어플리케이션에서 사용하는 데이터베이스 작업을 단순화하고, 데이터베이스와 객체 사이의 불일치를 해결하는 것입니다. 이를 통해 개발자는 복잡한 JDBC(Java Database Connectivity) 코드를 작성하는 대신, 더 간결하고 객체 지향적인 코드로 데이터베이스 작업을 수행할 수 있습니다. -chat gpt- chat gpt 선생님께서는 이렇게 설명하신다.역시나 정확하시다.
기존에는 spring jpa에 대해서만 좀 많이 사용하다보니 순수 jpa에 대해서는 관련해서 작성해보려고 합니다.
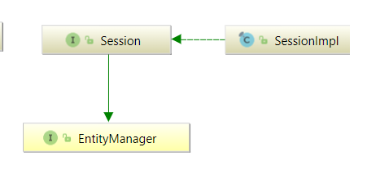
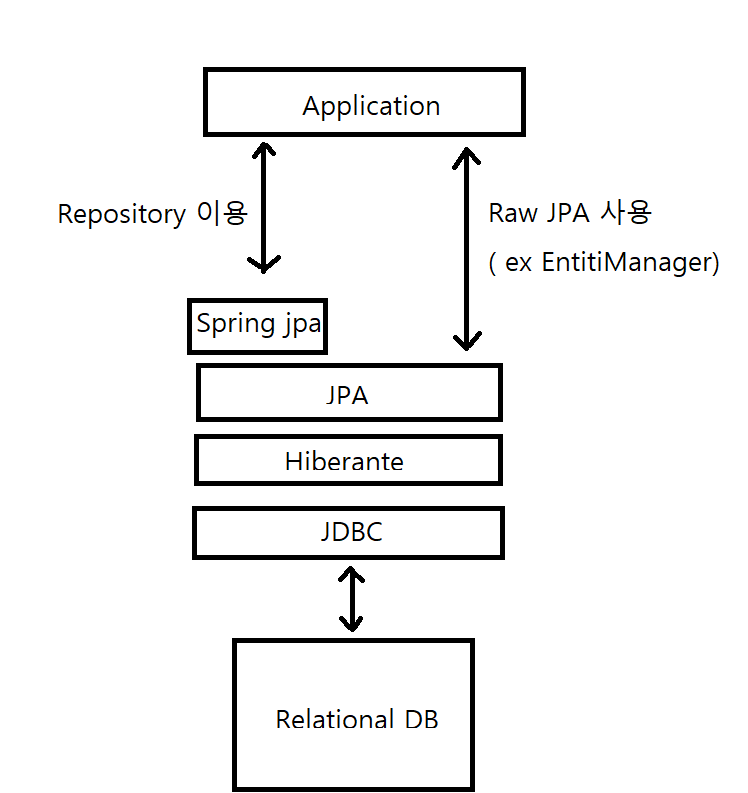
일단 아래 구조를 보겠습니다.
Spring 에서 제공하는건 Repository를 통해서 훨씬 편리하게 jpa를 이용했는데요. 순수하게 jpa를 사용하는 상황도 있겠죠. Spring 자체도 사람이 만든거라 완벽한게 아니기 때문에 알아둘 필요는 있을거 같습니다.
순수 자바 JPA 란? 순수 자바 JPA (Java Persistence API)는 자바 표준 ORM (Object-Relational Mapping) 기술입니다. JPA를 사용하면 자바 객체와 데이터베이스 테이블 간의 매핑을 구성하여, 객체 지향적인 방식으로 데이터베이스를 다룰 수 있습니다. 순수 JPA API를 사용하는 경우, Spring과 같은 추가 프레임워크에 의존하지 않고, JPA 스펙을 직접 구현하는 방식으로 작업합니다. 이러한 접근 방식은 애플리케이션의 데이터 접근 계층에서 높은 수준의 이식성과 유연성을 제공합니다.
사용 예시
persistence.xml 설정 파일 작성: JPA를 사용하기 위해서는 META-INF/persistence.xml 파일에 영속성 유닛 설정을 정의해야 합니다. 이 파일에는 데이터베이스 연결 설정, 엔터티 매니저 설정 등이 포함됩니다.
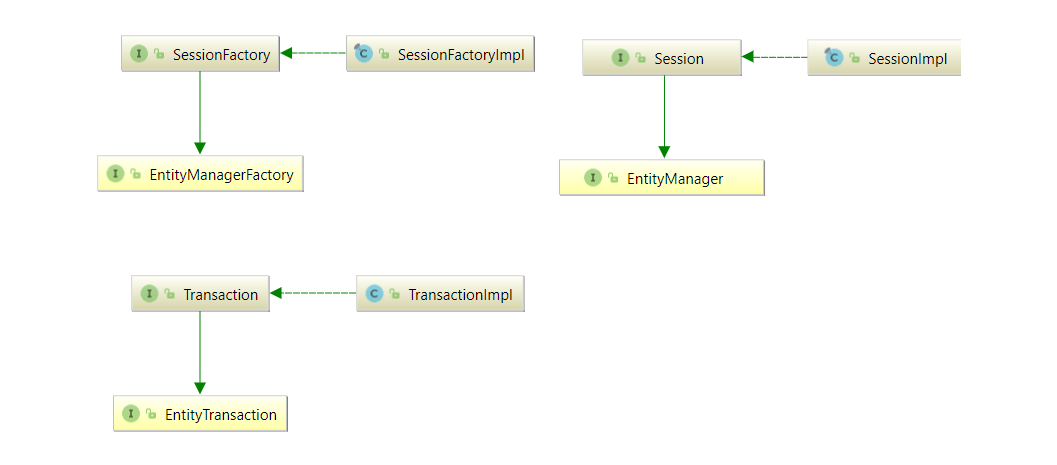
EntityManagerFactory 생성: 애플리케이션이 시작할 때 Persistence 클래스를 사용하여 EntityManagerFactory 인스턴스를 생성합니다. 이 인스턴스는 애플리케이션의 생명주기 동안 단 하나만 존재해야 합니다.
EntityManager 생성: 데이터베이스 작업을 수행할 때마다 EntityManagerFactory를 통해 EntityManager 인스턴스를 생성합니다. EntityManager는 데이터베이스 작업을 수행하는 데 사용됩니다.
트랜잭션 관리: 데이터베이스 작업을 수행하기 전에 트랜잭션을 시작해야 합니다. EntityManager를 사용하여 트랜잭션을 시작하고, 작업이 완료된 후에는 트랜잭션을 커밋하거나 롤백합니다.
엔터티 작업 수행: EntityManager를 사용하여 엔터티를 생성, 조회, 수정, 삭제하는 등의 작업을 수행할 수 있습니다.
리소스 정리: 작업이 완료되면 EntityManager를 닫고, 애플리케이션이 종료될 때 EntityManagerFactory를 닫아야 합니다.
EntityManagerFactory emf = Persistence.createEntityManagerFactory("YourPersistenceUnit");
EntityManager em = emf.createEntityManager();
em.getTransaction().begin();
// 엔터티 작업 수행
// 예: 엔터티 저장
MyEntity myEntity = new MyEntity();
em.persist(myEntity);
em.getTransaction().commit();
em.close();
emf.close();
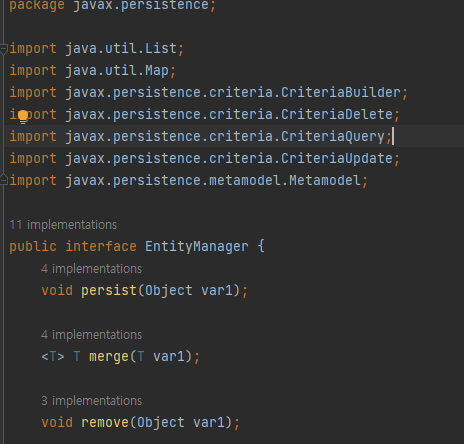
JPA API (Java Persistence API)란? JPA API (Java Persistence API)는 자바 애플리케이션에서 관계형 데이터베이스를 사용하는 방식을 표준화한 인터페이스 모음입니다. JPA는 자바 EE (Enterprise Edition)의 일부로, 자바 SE (Standard Edition) 애플리케이션에서도 사용될 수 있습니다. 이 API는 객체-관계 매핑 (ORM) 기능을 제공하여, 자바 개발자가 데이터베이스 테이블을 자바 객체로 매핑하고 관리할 수 있게 해줍니다
JPA API의 주요 목적과 기능
표준화된 ORM 지원: JPA는 엔터티(Entity)라고 하는 자바 객체와 데이터베이스 테이블 간의 매핑을 통해 ORM을 구현합니다. 이를 통해, 개발자는 데이터베이스 작업을 객체 지향적인 방식으로 수행할 수 있습니다.
데이터베이스 독립성: JPA를 사용하면 데이터베이스 작업을 데이터베이스에 특화된 SQL 문법 없이 수행할 수 있습니다. 이는 애플리케이션이 특정 데이터베이스 기술에 종속되지 않도록 해줍니다.
표준 API 제공: JPA는 EntityManager와 같은 일련의 API를 제공합니다. 이 API를 통해 엔터티의 생명 주기를 관리하고, CRUD (Create, Read, Update, Delete) 작업을 수행할 수 있습니다.
쿼리 언어: JPA는 JPQL (Java Persistence Query Language)과 Criteria API를 포함하여, 타입 안전 쿼리 작성을 지원합니다. 이를 통해 복잡한 조회 작업도 객체 지향적으로 처리할 수 있습니다.
트랜잭션 관리: JPA는 트랜잭션 관리를 위한 API를 제공합니다. 이를 통해 개발자는 데이터의 일관성을 유지하면서 데이터베이스 작업을 수행할 수 있습니다.
JPA 작동 원리
JPA의 핵심은 엔터티 매니저 (EntityManager)에 있습니다. 엔터티 매니저는 엔터티의 생성, 조회, 업데이트, 삭제 등의 작업을 관리합니다. 엔터티 매니저는 영속성 컨텍스트라는 컨테이너 안에서 엔터티의 생명 주기를 관리합니다. 영속성 컨텍스트는 엔터티의 상태를 관리하며, 데이터베이스와의 동기화를 담당합니다. 개발자는 JPA의 EntityManager를 사용하여 엔터티와 관련된 작업을 수행합니다. 예를 들어, 엔터티를 생성하고 데이터베이스에 저장하기 위해서는 persist 메소드를 사용하고, 데이터베이스에서 엔터티를 조회하기 위해서는 find나 JPQL, Criteria API 등을 사용할 수 있습니다. JPA를 사용함으로써, 개발자는 데이터베이스와의 상호작용을 추상화된 형태로 다루면서도, 데이터베이스 작업을 효율적이고 표준화된 방식으로 수행할 수 있게 됩니다. JPA는 개발자로 하여금 데이터베이스 작업에 드는 시간과 노력을 줄이고, 애플리케이션의 이식성과 유지보수성을 향상시키는 데 도움을 줍니다.
그렇다면 다음엔 hibernate, jpa, database 관계에 대해서 코드로 확인하며 작성해보도록 하겠습니다.
getDeclaredConstructor().newInstance()는 자바 Reflection API의 일부로 사용되며, 클래스의 새 인스턴스를 동적으로 생성할 때 사용됩니다. Reflection API를 사용하면 실행 시간(runtime)에 프로그램의 구조를 검사하고 조작할 수 있습니다. 이것은 특히 클래스의 타입이 컴파일 타임에 알려지지 않았을 때 유용합니다.
getDeclaredConstructor(): 이 메소드는 호출되는 클래스의 지정된 파라미터를 가진 생성자를 반환합니다. 파라미터가 없으면 기본 생성자를 반환합니다.
newInstance(): getDeclaredConstructor() 메소드로 얻은 생성자를 사용하여 클래스의 새 인스턴스를 생성합니다. 이 메소드는 해당 생성자의 public, protected, private에 관계없이 어떤 접근 제한자를 가진 생성자든지 인스턴스화할 수 있습니다.
getDeclaredConstructor().newInstance()를 사용하는 예제 코드입니다:
import java.util.HashMap;
import java.util.Map;
public class InstanceFactory {
private Map<String, Class<?>> classMap = new HashMap<>();
public InstanceFactory() {
// Here we map strings to classes
classMap.put("MyClass", MyClass.class);
// Add other classes to the map as needed
}
public Object createInstance(String key) throws Exception {
Class<?> clazz = classMap.get(key);
if (clazz != null) {
return clazz.getDeclaredConstructor().newInstance();
}
return null;
}
public static void main(String[] args) {
InstanceFactory factory = new InstanceFactory();
try {
Object myClassInstance = factory.createInstance("MyClass");
// Use myClassInstance as needed
} catch (Exception e) {
e.printStackTrace();
}
}
}
class MyClass {
// MyClass definition
}
문자열 키를 입력받고 classMap에서 해당하는 Class<?> 객체를 찾은 다음, 리플렉션을 사용하여 해당 클래스의 새 인스턴스를 생성하는 createInstance 메소드를 가지고 있습니다.
즉 classMap 키 값을 가지는 클래스들 put하여 다른 클래스들도 이용이 가능하겠죠.
예를들어 vehicle inteface가 존재한다면 class car, bus, train 을 상속받아 쓴다고 가정하면 손쉽게 클래스명의 hash 키를 통하여 동적으로 클래스 인스턴스를 생성하여 사용할수 있습니다.
자바에서 클래스나 인터페이스의 메타데이터를 읽어와서 실행 시간에 객체의 속성, 메소드, 생성자 등을 검사하거나 조작할 수 있게 해주는 기능입니다. 이 API를 사용하면 컴파일 타임에는 알려지지 않은 클래스의 객체를 생성하고, 메소드를 호출하며, 필드에 접근할 수 있습니다. 다시 말해서, 자바의 Reflection API를 사용하면 컴파일된 자바 코드 내부를 동적으로 탐색하고, 코드의 구조를 분석하며, 수정할 수 있게 됩니다.
Reflection API의 장단점
장점:
IDE나 디버깅 툴에서 코드의 구조를 분석할 때
컴파일 타임에 클래스의 타입이 결정되지 않는 프레임워크나 애플리케이션 개발 시
리플렉션을 이용해 특정 어노테이션을 분석하고 그에 따른 처리를 할 때
런타임에 사용자의 입력에 따라 다른 클래스의 메소드를 실행시키는 어플리케이션 개발 시
Reflection API의 중요 클래스와 인터페이스에는 Class, Method, Field, Constructor, Array, ReflectPermission 등이 있습니다. 예를 들어 Class 객체는 forName() 메소드를 통해 이름으로부터, 또는 .class 문법을 통해 직접 클래스를 로딩하여 얻을 수 있으며, 이를 통해 해당 클래스의 정보를 얻거나 객체를 생성할 수 있습니다.
단점:
Reflection API는 강력한 만큼 주의해서 사용해야 합니다. 이 API를 사용하면 private 멤버에 접근하거나 수정할 수 있어 보안 문제를 일으킬 수 있으며, 예외 처리를 제대로 하지 않을 경우 예기치 않은 문제를 야기할 수 있습니다. 또한, Reflection을 사용한 코드는 보통 직접적인 코드 호출보다 성능이 떨어지므로 성능에 민감한 애플리케이션에서는 사용을 자제하는 것이 좋습니다.
활용:
Reflection은 애플리케이션 개발보다는 프레임워크나 라이브러리에서 많이 사용된다. 프레임워크나 라이브러리는 사용자가 어떤 클래스를 만들지 예측할 수 없기 때문에 동적으로 해결해주기 위해 Reflection을 사용한다.
실제로 intellij의 자동완성, jackson 라이브러리, Hibernate 등등 많은 프레임워크나 라이브러리에서 Reflection을 사용하고 있다.
Spring Framework에서도 Reflection API를 사용하는데 대표적으로 Spring Container의 BeanFactory가 있다. Bean은 애플리케이션이 실행한 후 런타임에 객체가 호출될 때 동적으로 객체의 인스턴스를 생성하는데 이때 Spring Container의 BeanFactory에서 리플렉션을 사용한다.
Spring Data JPA 에서 Entity에 기본 생성자가 필요한 이유도 동적으로 객체 생성 시 Reflection API를 활용하기 때문이다. Reflection API로 가져올 수 없는 정보 중 하나가 생성자의 인자 정보이다. 그래서 기본 생성자가 반드시 있어야 객체를 생성할 수 있는 것이다. 기본 생성자로 객체를 생성만 하면 필드 값 등은 Reflection API로 넣어줄 수 있다.
자바에서 Executor와 ExecutorService는 자바의 동시성(concurrency) 프로그래밍을 위한 핵심 인터페이스입니다. 이들은 작업 실행을 추상화하여 개발자가 스레드 관리의 복잡성으로부터 벗어날 수 있게 돕습니다. 아래에서 각각에 대해 자세히 설명하겠습니다.
Executor
Executor 인터페이스는 java.util.concurrent 패키지에 속해 있으며, 단일 추상 메소드 execute(Runnable command)를 가지고 있습니다. 이 메소드는 주어진 작업(Runnable 객체)을 실행하는 방법을 정의합니다. Executor를 구현하는 클래스는 이 execute 메소드를 통해 어떻게 그리고 언제 작업을 실행할지 결정합니다. 이 인터페이스는 작업의 실행을 간단하게 추상화하여, 실행 메커니즘(예: 스레드 사용 방법)을 사용자로부터 숨깁니다.
Executor executor = anExecutor;
executor.execute(new Runnable() {
public void run() {
// 작업 내용
}
});
Executor 인터페이스는 개발자들이 해당 작업의 실행과 쓰레드의 사용 및 스케줄링 등으로부터 벗어날 수 있도록 도와준다. 단순히 전달받은 Runnable 작업을 사용하는 코드를 Executor로 구현하면 다음과 같다
ExecutorService는 Executor를 확장한 더 복잡한 인터페이스로, 생명주기 관리(lifecycle management)와 작업 실행 결과를 추적할 수 있는 기능을 제공합니다. ExecutorService를 사용하면, 비동기 작업을 제출하고, 작업이 완료될 때까지 기다리며, 작업 실행을 취소하고, 실행자 서비스를 종료할 수 있습니다. ExecutorService에는 작업을 제출하기 위한 다양한 submit 메소드가 있으며, 이들은 Future 객체를 반환하여 나중에 작업의 결과를 검색할 수 있게 합니다.
ExecutorService는 주로 다음과 같은 메소드들을 제공합니다:
shutdown(): 실행자 서비스를 순차적으로 종료시키며, 이미 제출된 작업은 실행되지만 새 작업은 받지 않습니다.
shutdownNow(): 실행자 서비스를 즉시 종료시키며, 대기 중인 작업은 실행되지 않습니다.
submit(Callable<T> task): 값을 반환할 수 있는 작업을 제출하고, 작업이 완료될 때 결과를 받을 수 있는 Future<T>를 반환합니다.
invokeAll(...): 작업 컬렉션을 실행하고, 모든 작업이 완료될 때까지 기다린 후, 결과를 반환합니다.
이미지 출처 : : https://mangkyu.tistory.com/259
ExecutorService 인터페이스에서 제공하는 주요 메소드들과 각각의 사용 예제를 아래에 설명하겠습니다. 이 인터페이스는 다양한 방법으로 작업을 실행하고, 관리하는 기능을 제공합니다